|
||||
|
Більш складні статистичні методиВище ми описали базові статистичні методи аналізу даних, якими повинен володіти кожен дослідник. Проте, арсенал сучасної статистики включає в себе чимало інших, більш складних методів, яким присвячена спеціальна література. Ми описово зупинимося на деяких з них, щоб дати загальне уявлення, куди слід рухатися, якщо при аналізі ваших даних виникне ситуація, коли описаних методів не вистачає для відповіді на запитання експериментатора. Досить часто експеримент будується таким чином, що досліджуваний фактор (або кілька факторів) може приймати кілька різних фіксованих рівнів значень. Виявлення ефекту даного фактора може бути здійсненим за допомогою парних або незалежних порівнянь, проте, якщо ми вивчаємо вплив фактора на кілька різних параметрів одночасно, і фактор приймає більше, ніж два, рівня значень, нам потрібно здійснити чималу кількість порівнянь, що може бути досить трудомістким. Крім того, здійснюючи багато порівнянь одночасно ми стикаємося із проблемою зростання ймовірності здійснити статистичну помилку першого роду (відкидання нульової гіпотези, коли вона справедлива). Якщо прийнятий нами рівень значущості 0.05 і ми здійснюємо одне порівняння, ймовірність помилитися становить, відповідно, 5%. Якщо ж ми одночасно здійснюємо 100 порівнянь, ймовірність помилитися хоча б один раз становить вже 99.4%, тобто ми практично гарантовано здійснимо помилку. В такому випадку необхідно застосовувати алгоритми корекції ефекту множинних порівнянь. Одним з методів аналізу даних в такій моделі є дисперсійний аналіз або ANOVA (ANalysis Of VAriance). Методи ANOVA розглядають кількісні дані як суму внеску ефекту дії досліджуваного фактора та певної випадкової величини. Відповідно, основне питання полягає у тому, яка частина вибіркової дисперсії обумовлена саме дією фактора, що нас цікавить, - якщо вона істотна, ми визнаємо ефект дії фактора значущим. При однофакторному дисперсійному аналізі (One-way ANOVA) обчислюється статистика F, яка відображає співвідношення дисперсії, обумовленої дією аналізованого фактора, та "випадкової" дисперсії. За цією статистикою обчислюється рівень значущості р, на основі якого ми робимо висновок про гомогенність аналізованих вибірок, тобто відсутність впливу фактора, або ж протилежний. Приклад однофакторного дисперсійного аналізу, застосованого у програмі PSPP до вже аналізованих олімпіадних оцінок.
В даному випадку в якості фактора для аналізу ми обрали регіон України, в якому навчалися учні.
Можна бачити, що р = 0.005, тобто фактор "регіон" значущо впливає на результати учнів.
Тепер для того, щоб виявити, учні яких областей країни показали відносно кращі результати,
потрібно застосувати одну з процедур post-hoc аналізу. Такими процедурами можуть бути попарні (не плутати з парними)
порівняння вибірок за допомогою t-тесту
або ж спеціалізовані процедури множинного порівняння (Multiple Range Tests),
які враховують ефект множинних порівнянь. Як правило, вони видають матрицю, в якій вибірки з подібними результатами
об'єднуються у гомогенні групи. В даному випадку матриця виглядає таким чином:
Видно, що найкращі результати (за середнім значенням Mean) показали учні Волинської області (VOL), проте, результати цих учнів значущо відрізняються лише від результатів трьох регіонів (хрестик у стовпчику позначає гомогенну групу, яких у цій матриці чотири). Зауважимо, що в даному випадку без використання ANOVA для того, щоб порівняти кожну область з кожною іншою, ми повинні були б провести 600 попарних порівнянь. Дисперсійний аналіз застосовується до нормально розподілених кількісних даних. Для інших числових даних
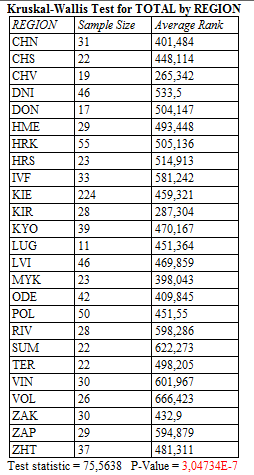
існують еквівалентні рангові процедури, наприклад, тест Краскелла-Уолліса. Його статистика обчислюється
на основі рангів груп даних. Результат його виконання наведено нижче:
Можна бачити, що як і у випадку застосування ANOVA гетерогенність результатів в залежності від регіону є статистично значущою (значення р), а найкращий результат (найвищий середній ранг) також у учнів Волинської області. Даний тест є більш простим, проте не дозволяє розділити дані на гетерогенні групи. Для цього слід використати попарні рангові порівняння, наприклад, критерій Манна-Вітні. Незважаючи на це, процедура може істотно скоротити час аналізу даних, якщо більша їх частина належить до гомогенних груп. Ускладненням задачі однофакторного аналізу є двофакторний аналіз - коли на досліджуване явище одночасно діють два фактори, кожен з яких приймає значення різних рівнів. При цьому зміни досліджуваної величини можуть бути обумовленими як дією фактора А, так і дією фактора Б, а також їх взаємодією, яка може давати позитивний (ефект А+Б більше, ніж А і Б окремо) або негативний (ефект А або Б окремо більше, ніж сумісний ефект А+Б) результати. Методи вирішення такої задачі називаються двофакторним дисперсійним аналізом (Two-way ANOVA). В більш складному випадку на досліджуваний об'єкт можуть діяти більше, ніж два фактори. В такому випадку допоможуть складні методи багатовимірного аналізу. Інший клас статистичних задач виникає тоді, коли ми не можемо напряму побачити фактор(и), який обумовлює реєстровані ефекти, а лише спостерігати наслідки його дії. В деяких випадках нам невідомо навіть число таких факторів. Подібні задачі часто виникають в соціології, оскільки причини, що впливають на поведінку суспільства, далеко не завжди очевидні. В такому випадку застосовують методи факторного аналізу (Factor Analysis). Їх не слід плутати з пригаданими вище одно- та двофакторними дисперсійними аналізами, коли нам відомо, які фактори діяли на експериментальні об'єкти. Метою дисперсійного аналізу є встановлення ступеня впливу вже відомих та експериментально виміряних факторів. Натомість, метою факторного аналізу є виявлення невідомих нам одного чи кількох факторів, що впливають на досліджувані парамери. Кластерний аналіз дозволяє класифікувати сукупність наших даних на основі їх величин,
групуючи подібні точки за їх подібністю.
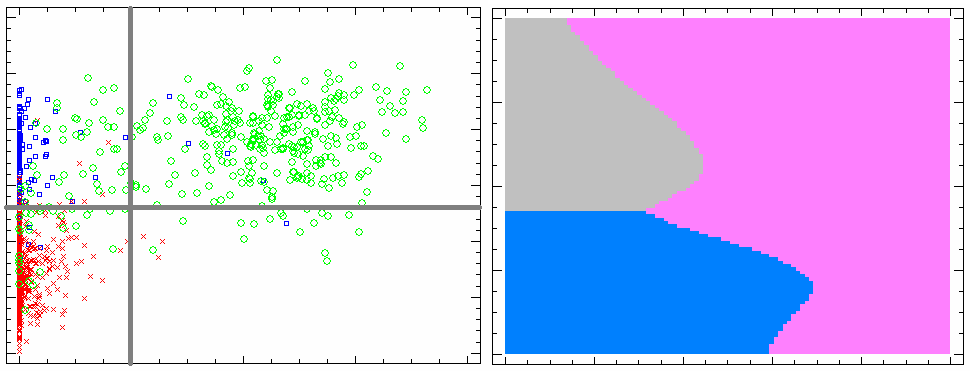
Результат виділення кластерів виглядає таким чином:
Зліва зображено набір аналізованих даних, класифікованих "вручну" (параметри функціонування головного мозку та різні фази циклу сон-неспання), справа - ті ж дані, проаналізовані автоматичним алгоритмом. Можна бачити, що "ручний" та автоматичний аналізи дають подібні результати, натомість автоматичний в десятки разів швидший. Для виділення кластерів часто застосовуються алгоритми нейромереж. Окремий клас статистичних задач становить аналіз часових рядів - вивчення зміни різних параметрів в часі. При цьому дослідників можуть цікавити наявність періодичних процесів (регулярні спади та наростання) та наявність трендів (тенденції до зростання або спадання). |
|
||


|
||||