|
||||||||||||||||||||||
|
Порівняння вибірокПорівняння двох вибірок (двовибіркові порівняння), тобто наборів даних, отриманих у експериментах, що відрізняються, як правило, одним параметром, є однією з найбільш поширених практичних задач дослідника. Розрізняють парні та незалежні порівняння. Про парні порівняння ми говоримо, коли порівнюємо залежні вибірки, тобто такі, в яких окремі виміри логічним чином об'єднані в пари. Наприклад, ми хочемо перевірити, чи міняється частота пульсу після фізичних вправ (звісно, що повинна зростати). Для цього ми реєструємо пульс обстежуваних людей до (у стані спокою) та після вправ (наприклад, кількох присідань). Таким чином, в результаті експерименту у нас будуть отримані пари значень. При формуванні таблиць для наступного аналізу результати вимірювань властивостей кожного об'єкту вносяться у один і той же рядок, а різні стовпчики відповідають різним вимірюванням. Приклад заповнення такої таблиці:
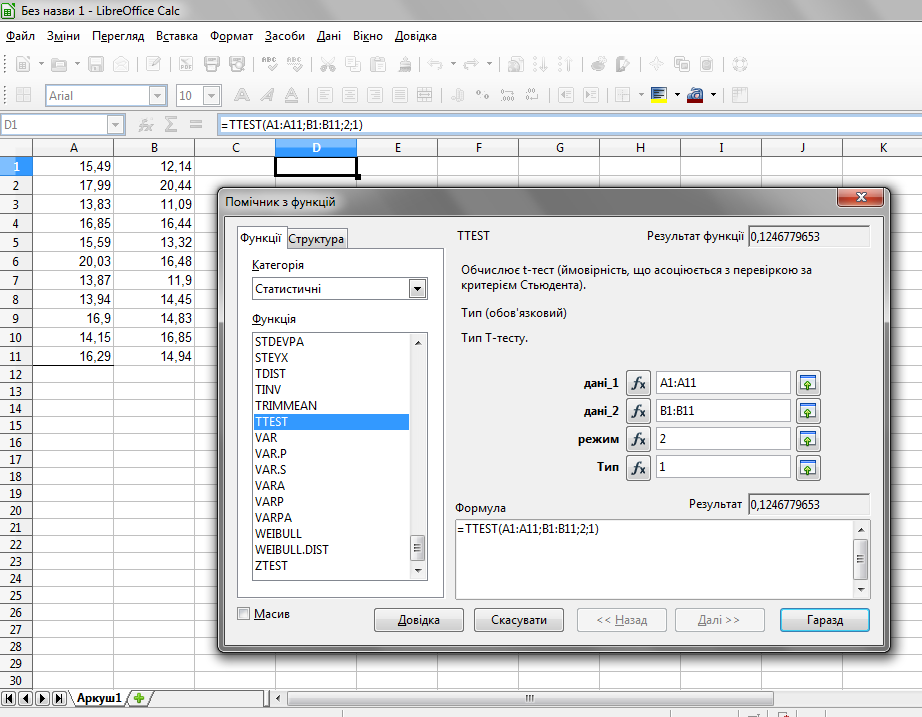
В такий спосіб можна тестувати вплив різноманітних чинників на різні об'єкти, головною умовою є допустимість повторного тестування після впливу досліджуваного фактору. Натомість, при незалежному порівнянні ми досліджуємо два набори даних, які прямо не пов'язані між собою. Прикладом може бути сформульоване раніше порівняння зросту школярів різного віку. Подібного роду задачі виникають, коли ми тестуємо людей, що відрізняються статтю (чоловіки, жінки), станом здоров'я (здорові, пацієнти з певною хворобою), віком (молоді, похилі) та ін. В цьому випадку принципово не можна провести парне порівняння. При формуванні таблиць для аналізу, стовпчики відповідають різним групам, а у рядках містяться непов'язані між собою виміри різних об'єктів. Також дані вимірів досліджуваного параметру можна внести у один стовпчик, а у інший коди, які відповідають позначкам груп. Зауважимо, що залежні вибірки принципово можна аналізувати методами незалежного порівняння, хоч вони дадуть більшу помилку другого роду, тоді як незалежні дані принципово не можна аналізувати парними методами. Окрім двовибіркових порівнянь може існувати задача одновибіркового порівняння, коли нам потрібно встановити рівність наших даних з певним еталонним значенням. Зауважимо, що парні двовибіркові порівняння легко зводяться до одновибіркових - для цього потрібно обчислити різницю пар значень і порівняти отриману вибірку з нулем (або ж поділити одне значення на інше та порівняти отриманий масив із 1). Як правило, статистичні програми мають у своєму арсеналі набір тестів і для парних, і для незалежних порівнянь. Порівняння нормальних данихПорівняння нормально розподілених даних здійснюється за допомогою t-критерію (або критерію Стьюдента). Ця процедура є найбільш поширеною з статистичних тестів. Для застосування вона вимагає дотримання ряду умов. По-перше, обидві порівнювані вибірки повинні бути розподіленими за нормальним законом. По-друге, їхній розкид, який ми оцінюємо за дисперсією, повинен також бути однаковим. У випадку нерівних дисперсій алгоритм тесту трохи міняється. Якщо тест на нормальність дав негативний результат, застосовувати t-критерій не можна, і дані слід аналізувати за допомогою непараметричних критеріїв або ж застосувати процедуру нормалізації (див. далі). Алгоритм обчислення значення t-критерію (за умови рівності дисперсій) є досить простим: Як в ситуації незалежних порівнянь, так і при парних порівняннях при справедливості нульової гіпотези (тобто рівності обох вибірок) значення статистики критерію дорівнює 0, і чим воно є більшим, тим меншою є ймовірність справедливості нульової гіпотези. Алгоритм обчислення одновибіркового критерію є дещо іншим, з ним можна ознайомитися за посиланням. На основі обчисленого значення t статистична програма обраховує величину р. У випадку, якщо р ≤ 0.05, ми відкидаємо нульову гіпотезу і робимо висновок, що порівнювані вибірки є значущо відмінними. Для обчислення параметрів t-тесту у програмі LibreOffice Calc потрібно викликати функцію TTEST: Її параметрами є два набори даних, що беруться з таблиці, режим порівняння (1 = односторонній / 2 = двосторонній, якщо немає спеціальних умов, слід зазначати 2), тип порівняння (1= парне, 2 = непарне з рівними дисперсіями, 3 = непарне з різними дисперсіями). Для перевірки рівності дисперсій застосовується функція FTEST, параметрами якої є два набори даних, а результатом - р порівняння двох дисперсій (визнаються нерівними при р ≤ 0.05; в такому випадку у функції TTEST слід використовувати тип порівняння = 3). Як можна бачити на рисунку, для зазначеного набору даних обчислене значення р = 0.12, що є більшим за рівень значущості, отже ми не маємо підстав відкинути нульову гіпотезу і визнаємо рівність двох вибірок. У програмі PSPP слід скористатися пунктом меню "Аналіз" - "Порівняти середні" з доступними опціями:
Перевірка парних вибірок також може бути здійсненою для багатьох пар одночасно.
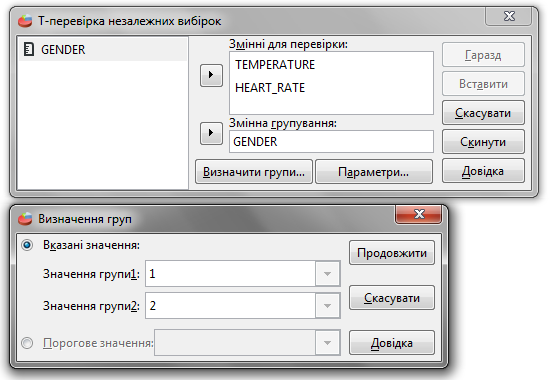
Приклад результатів парного порівняння (вибірки записані у стовпчики VAR001 і VAR002): Можна бачити не лише значення р (останній стовпчик нижньої таблиці), а і статистику t, а також середнє арифметичне, стандартні відхилення (σ) та помилку (m) різниці двох вибірок. Це додає нам зручності при інтерпретації результатів, адже мало знати, що дві вибірки є різними, потрібно знати, в який бік (збільшення чи зменшення) зрушився досліджуваний параметр. Для здійснення незалежних порівнянь дані слід організувати дещо іншим чином - помістити усі значення в один стовпчик і створити другий стовпчик з кодами, які визначають належність елемента до тої чи іншої вибірки. Наприклад, проаналізуємо дані вимірювання температури тіла та пульсу у групи людей. Колонка GENDER містить інформацію про стать обстежуваних людей в кодах 1 = чоловіки, 2 = жінки. Заповнення вікон введення даних при цьому виглядає таким чином: Змінні для перевірки - дані, які ми хочемо порівнювати. Змінна групування - стовпчик із кодами. Перед тим, як почати аналіз, слід визначити порівнювані групи - явно вказавши значення змінної групування для обох порівнюваних груп, або ж розділивши вибірки на дві частини за пороговим значенням змінної групування (тоді порівнюватимуться вибірки із значенням цієї змінної нижче порогу та вище або рівне порогу). Результат порівняння виглядає наступним чином: Верхня таблиця містить статистику двох груп для кожного аналізованого параметру. Нижня таблиця містить результат порівняння вибірок. Спочатку наведено результат перевірки рівності дисперсій - у стовпчику "Знач" ми бачимо, що для параметру HEART_RATE вони не рівні, отже слід використовувати рядок "Не припускаємо рівність дисперсій". Далі у стовпчику "Знач. (двобічна)" наведено рівень значущості для порівнянь двох вибірок. Бачимо, що з р = 0.022 температура тіла жінок значущо перевищує таку чоловіків (♀ 36.89±0.41 та ♂ 36.73±0.39 за верхньою таблицею). За пульсом значущої різниці між чоловіками і жінками не встановлено. |
|
||||||||||||||||||||


|
||||||||||||||||||||||
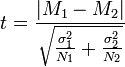 ,
,