
|
||||
|
Представлення данихГотуючи свої результати до презентації або публікації, слід продумати, як ви представлятиме ваші дані. Існує кілька стандартів представлення структури даних у числовій або графічній формі. Нормально розподілені дані в тексті представляють у форматі М±σ, наприклад: "вік студентів 1 курсу становить 17.0 ± 0.6 років". Таким чином, ми зазначаємо центральну тенденцію (М) та характеристику розкиду даних, тобто відхилення індивідуальних даних від середнього (σ). Досить часто, особливо у вітчизняних публікаціях за традицією, дані описують у форматі М±m, що є не зовсім коректним. Образно кажучи, М±σ характеризує, наскільки далеко від центрального значення можуть знаходитися ваші дані. Натомість, М±m характеризує, наскільки далеко від середнього арифметичного вашої вибірки може знаходитися середнє генеральне, тобто описує не отримані вами дані, а генеральну сукупність. В ряді випадків (застосування спеціалізованих статистичних критеріїв) розкид даних може характеризуватися за допомогою обчислених довірчих інтервалів - меж, в яких з певною ймовірністю містяться параметр генеральної сукупності, тобто "істинне" значення аналізованого параметра. Іншими словами, це межі того, наскільки ми можемо "вірити" нашим даним, наскільки вони відображають реальний стан речей. Стандартно ймовірністю побудови довірчих інтервалів вважають 95%, проте в залежності від задач дослідження можуть використовувати 99% або інші значення. Зрозуміло, що чим вище ймовірність, тим вужчим буде обчислений довірчий інтервал. Зауважимо, що межі ±m є одним з варіантів довірчих інтервалів, його ймовірність є досить низькою - близько 67%. Інші типи довірчих інтервалів позначаються LSD (Least Significant Difference), Tukey HSD (Honestly Significant Difference) та ін. Дані, що не розподілені за нормальним законом, описуються середнім арифметичним неточно.
На це впливає, у першу чергу, зміщення розподілу експериментальних даних (високий коефіцієнт асиметрії).
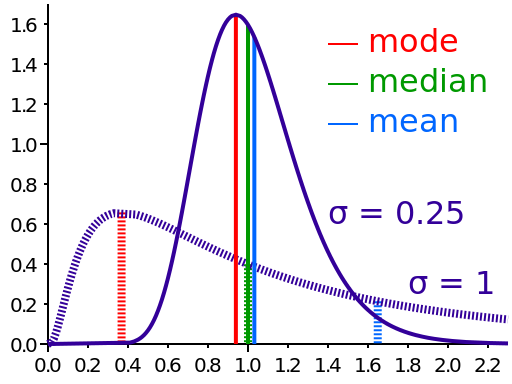
На наступному рисунку зображено два асиметричних розподіли. Можна бачити, що усі три міри центральної тенденції в даних випадках мають різні значення. Мода завжди указує на значення, що зустрічається найбільш часто. Вона погано дозволяє оцінити вибірку в цілому, не відображає значення, що зустрічаються рідше. Середнє арифметичне істотно змінюється при наявності у вибірці значень, які сильно відрізняються від основного масиву даних в більший (як в наборі даних, зображеному перервною лінією) або менший бік. Зважаючи на це, медіана - значення, яке ділить набір даних на дві рівні частини - є найбільш адекватною характеристикою центру даних. Розкид даних характеризується квартилями - величинами, які відсікають по 25% найменших і найбільших значень вибірки.
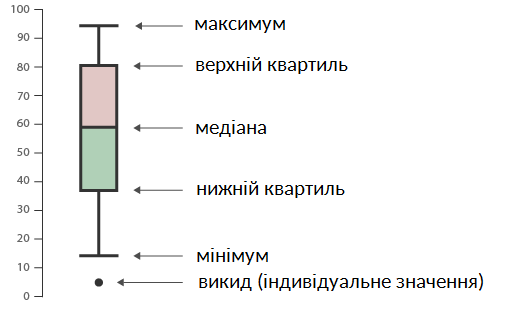
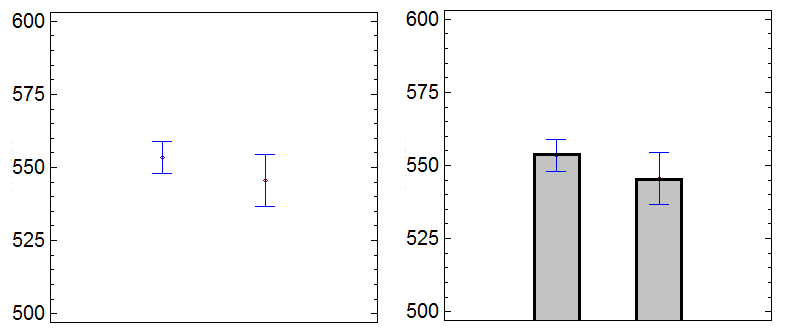
Запис результатів при цьому здійснюється у форматі Графічне представлення данихСтатистичні і табличні програми містять чималий арсенал для графічного представлення даних. Існують спеціалізовані програми, призначені саме для візуалізації даних. Також, в мережі Інтернет доступні сайти, на яких можна безкоштовно (і за гроші) побудувати різнопланові інфографіки, наприклад http://www.datacopia.com/https://www.meta-chart.com/ та інші. Найбільш інформативним типом діаграми є "коробки з вусами" (box-and-whiskers plot). Діаграми такого типу можуть зображатися горизонтально або вертикально. Розмір "коробки" відповідає відстані між нижнім і верхнім квартилями, що називається міжквартильним розмахом. Відстань між кінцями "вусів" відповідає усьому діапазону даних, які спостерігалися в експерименті (від мінімума до максимума). В деяких випадках статистичні програми можуть розцінювати певні значення, що сильно вибиваються з основного масиву даних, як викиди (outliers). Вони можуть позначатися окремими точками, що лежать за межами "вусів". В залежності від типу експериментальних даних наявність викидів може бути наслідком високої індивідуальної варіабельності досліджуваного параметра або ж результатом помилки в експерименті (в цьому випадку такі дані слід виключити з подальшого аналізу). Слід зауважити, що саме наявність викидів істотно впливає на середнє арифметичне, натомість, медіанне значення вибірки є стійким до них. Окрім перелічених показників на даному типі діаграм можуть бути позначені і середні арифметичні значення - хрестиком або іншою позначкою. Як правило, середнє арифметичне розташоване всередині "коробки" ближче чи далі від медіани, залежно від ступеня асиметричності розподілу даних. Нормально розподілені дані часто зображаються у формі стовпчиків, висота яких позначає середнє значення, з "вусами", розмах яких дорівнює ±σ. Стовпчики діаграм можуть не зображатися, тоді середнє значення позначатиметься точкою.
Для кращого розуміння у легенді рисунка (підписі до нього) зазначається, який саме параметр обрано для візуалізації "вусами" - середньоквадратичне відхилення або довірчий інтервал. 
|
|
||


|
||||
{kind=link}