
|
||||
|
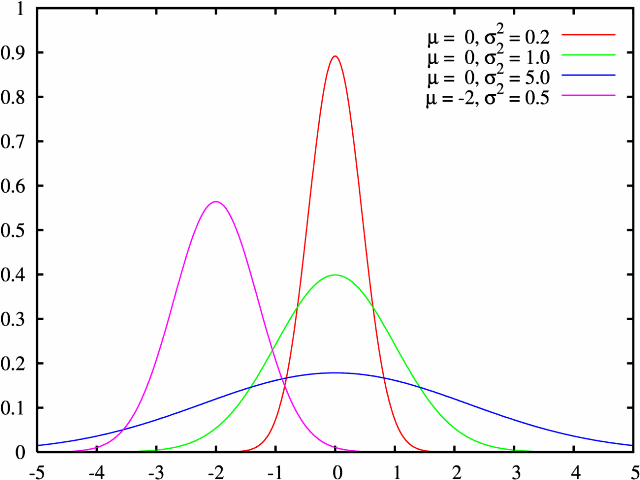
Якими бувають вибірки. Вибірки "нормальні" і "ненормальні"Вибірки можна характеризувати різними способами, одним з яких є характер розподілу даних всередині неї. Під розподілом даних ми розуміємо ту закономірність, що описує, скільки разів у вибірці зустрічається те або інше значення. Від цього часто залежить те, які статистичні методи ми можемо застосовувати для аналізу цієї вибірки. В більшості випадків для нас є важливим, чи підходить розподіл даних всередині вибірки під так званий "нормальний розподіл". Крива нормального розподілу (або крива Гаусса) характеризується тим, що існує певне центральне максимальне значення досліджуваного параметра, і частота зустрічі інших значень тим менше, чим далі це значення від центрального. В теорії ця крива є нескінченною в обох напрямках (до +∞ і -∞) і симетричною. Такий розподіл спостерігається, коли експериментальні дані є кількісними, їх достатньо багато, і відхилення від центрального значення залежить від випадкових факторів.
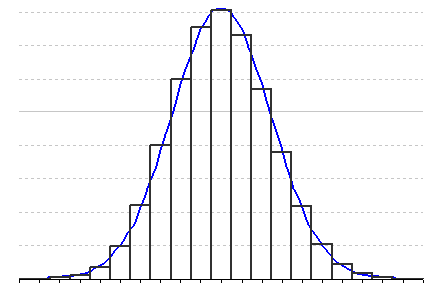
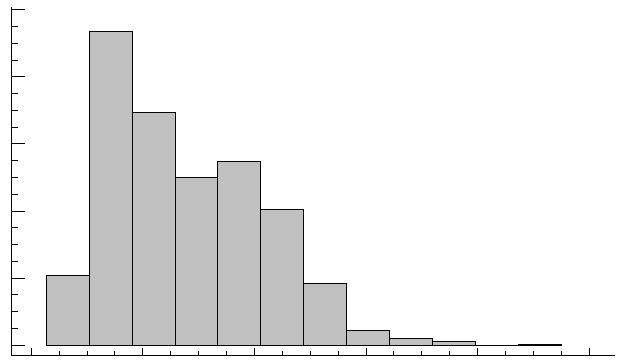
Слід зазначити, що слово «нормальний» в даному контексті не несе звичайного змісту. Дані, розподілені не за нормальним законом не стають від цього «ненормальними» чи неправильними. З практичних міркувань часто буває складно побудувати криву розподілу експериментальних даних, виходячи з безпосередніх вимірів, особливо за умов недостатнього обсягу вибірки. В такому випадку будують гістограми розподілу, які являють з себе набір стовпчиків різної висоти. Весь діапазон значень досліджуваного параметра (від мінімума до максимума) розбивають на кілька інтервалів. Відрізок вісі абсцис, який відповідає певному інтервалу є основою стовпчика, а його висота відповідає кількості (абсолютній чи відносній) елементів вибірки, що потрапили в цей діапазон. Зрозуміло, що від вибору ширини інтервалів, за якими будується гістограма розподілу, буде істотно залежати її зовнішній вигляд. Більшість статистичних програм самостійно вирішують це питання для отримання найкращих результатів.
Для чого потрібно знати, як розподілені наші дані?Математиками розроблено багато алгоритмів вирішення різних статистичних задач. Деякі з них вирішуються більш точно (або взагалі хоч якось) лише за умови, якщо дані розподілені за нормальним законом. Відповідно, такі статистичні методи можна застосовувати тільки до вибірок з нормальним розподілом. Такі методи називаються параметричними, оскільки їх результати залежать від параметрів розподілу даних. На відміну від них, існують методи, для застосування яких не потрібно ніяких додаткових умов. Такі методи називаються непараметричними. Виникає питання: а чому ж не можна використовувати тільки непараметричні методи? Причиною цього є більша потужність параметричних методів – вони дають більш достовірні результати, з меншою ймовірністю помилитися, деякі ж задачі взагалі не можна вирішити, якщо розподіл даних не є нормальним. Як визначити, чи належать ваші дані до нормальних?Крива нормального розподілу описується математичною формулою, а тому її параметри точно відомі. Існують спеціалізовані критерії (див. далі), що призначені для оцінки належності вибірки до нормальних. Більш просто (але менш точно) належність вибірки до нормальних можна за параметрами асиметрії та ексцесу, суть яких описана далі. |
|
||


|
||||
{kind=link}