|
||||||||||||||||||||||||||||||||||||||||||||||||||
|
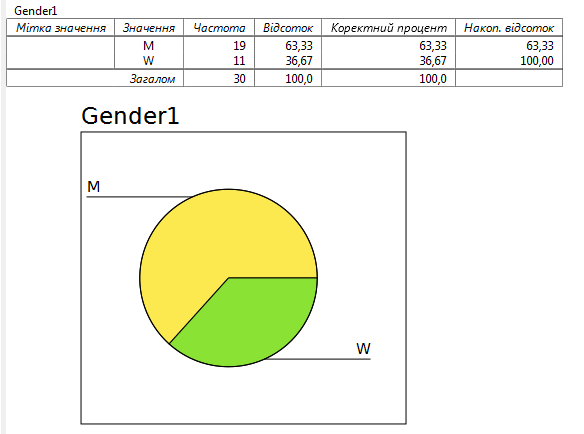
Опис параметрів вибірокПерш, ніж порівнювати різні вибірки між собою або здійснювати будь-які інші аналітичні дії, слід зрозуміти структуру ваших даних та описати їх. Методи, які описують структуру даних, називаються дескриптивною статистикою (від англ. description). Дані, виміряні у різних шкалах, можуть і повинні бути описані різними способами. Крім числової форми, яка є обов'язковою для аналізу (і представлення у наукових публікаціях), для більшої наочності дані можуть бути представленими у графічній формі. Номінальна шкалаДані, виміряні у цій шкалі, найпростіше згрупувати по категоріям та порахувати частоти - загальну кількість елементів кожної з них. Наприклад, якщо ми хочемо схарактеризувати гендерну структуру певної групи людей, нам потрібно порахувати, скільки у цій групі чоловіків та жінок (дві категорії). З метою наступного порівняння з іншими аналогічними вибірками дані потрібно нормувати - перевести у відсоткове представлення. Після цього значення частки різних категорій не будуть залежати від обсягу вибірки.
За допомогою обчислення частот категорій можна аналізувати також порядкові і кількісні дані. Для цього потрібно перетворити їх у номінальну форму. Приміром, ми аналізуємо IQ двох груп людей. За методикою однієї з поширених версій цього тесту - тесту Айзенка - максимальний бал становить 180, мінімальний - 0. Проте, така порядкова шкала може бути трансформованою у номінальну: IQ від 0 до 90 - низький, 90-110 - середній, 110-180 - високий. Залежно від суті аналізованої величини, вона може бути приведена до різної кількості номінальних категорій. Проте, аналіз числових даних дає нам більше можливостей, ніж аналіз категорій. Незважаючи, що порядкові дані не є кількісними, за умови достатньої кількості спостережень (тобто обсягу вибірки) та порівняно великої кількості можливих значень, які можуть бути отриманими в результаті спостереження або експерименту, вони можуть аналізуватися кількісними методами. Однозначного правила, яке б встановлювало, яка деталізація шкали вимірювання дозволяє використовувати кількісні методи, не існує, таке рішення повинен приймати дослідник на основі розуміння суті даних, їх структури, задач дослідження та традицій дослідження у певній галузі. Наведемо приклад: навчальні оцінки в традиційній університетській шкалі ("5", "4", "3", "2" або "відмінно", "добре", задовільно", "незадовільно") категорично не можуть вважатися кількісними даними; натомість, оцінка в сучасній шкільній системі (від 1 до 12) за певних умов може вважатися кількісною (хоч і з багатьма умовами та ризиками отримати недостовірні результати); тести ЗНО з більшості предметів дозволяють отримати "сирі" оцінки від 48 (математика) до 104 (укр. мова та література) балів, що дозволяє більш впевнено використовувати кількісні методи. Числові даніЧислові дані (виміряні у кількісній шкалі або прирівняні до неї порядкові дані) можна описати рядом статистичних параметрів, перелік яких ми наведемо нижче. З описових статистик можна виділити ті, що характеризують центральну тенденцію даних (найбільш типове, найбільш часто спостережене значення), та ті, що характеризують розкид даних (тобто, те, наскільки весь масив даних скупчений навколо центральної міри або віддалений від неї). Ми не наводимо формули для обчислення статистик, оскільки їх можна знайти у доступних джерелах (наприклад, Вікіпедії), а на практиці ці показники обчислюються спеціалізованими програмами.
В пакеті LibreOffice описові статистики обчислюються або відповідними функціями, які можна знайти в розділі "Статистичні", або ж за допомогою пункту меню "Дані" - "Статистика" - "Описова статистика". В PSPP відповідний пункт меню називається "Аналіз" - "Описова статистика" - "Описова статистика". |
|
||||||||||||||||||||||||||||||||||||||||||||||||


|
||||||||||||||||||||||||||||||||||||||||||||||||||